*This is the final in a series of posts from Dr Michael Piotrowski, one the recipients of the DM2E Open Humanities Awards – Open track. You can find the final report here.*
Europäische Friedensverträge der Vormoderne online (“Early Modern European Peace Treaties Online”) is a comprehensive collection of about 1,800 bilateral and multilateral European peace treaties from the period of 1450 to 1789, published as an open access resource by the Leibniz Institute of European History (IEG). The goal of the project funded by the DM2E-funded Open Humanities Award is to publish the treaties metadata as Linked Open Data, and to evaluate the use of nanopublications as a representation format for humanities data.
The Final Countdown
Due to the problems at the outset of the project (see my first blog post), we lost about a month, and with the holiday season in between, it’s hard to catch up. So we’ve always been trailing behind the other projects, or at least that’s what it felt like when reading their status updates.
On Friday we finally got the virtual machine to run our stuff on. We had ordered the VM from our computing center before Christmas, but an acute shortage of personnel our order was delayed by several weeks. We immediately started setting up the software and migrating the data from the development machine to the production server and had it up and running by midnight…
We now have Fuseki running on http://data.ieg-friedensvertraege.de. Since you can’t really “see” Linked Open Data, we’ve also set up Pubby, a Linked Data frontend for SPARQL endpoints, which gives the data a friendlier face. For example, the screenshot below shows how the information on the Friedenspräliminarien von Breslau (in English known as Treaty of Breslau) is presented in Pubby.
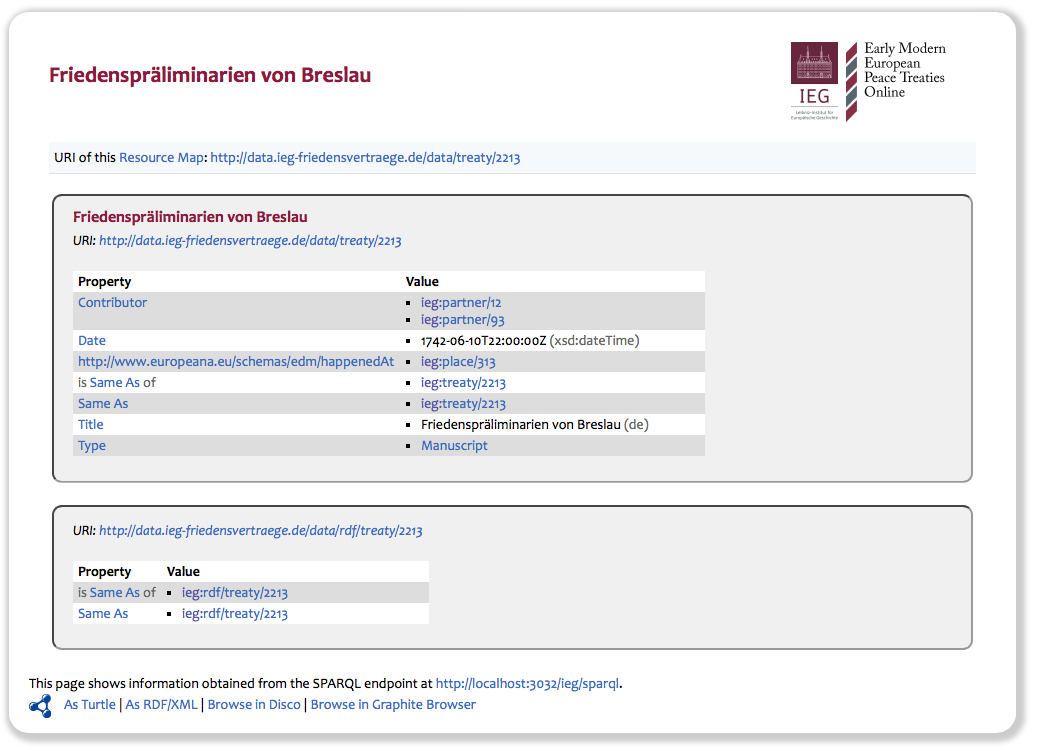
You may note that there are still some errors, and in fact the published state of the data is not quite final at this point—we’re still working on some last-minute issues—but it should give you an idea.
Onging Work
Still missing in this version are links to other LOD sources, but these will be there after the next update in a few days.
As I’ve said above, you can’t really “see” the data, so there isn’t really much to show; what is exciting is the potential it has for automatic processing. As a very low-key example, the homepage at http://data.ieg-friedensvertraege.de currently shows a “live” list of all treaty partners, i.e., when you load the Web page, a query is sent to the SPARQL endpoint to retrieve all entities of typeedm:Agent 1. We’re planning to replace this rather boring list with something more interesting, for example, a map showing the treaty locations, which could look like this:
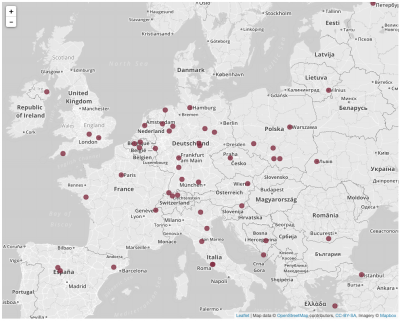
However, this will need to wait for the next update, because it is currently not possible to automatically retrieve the geographical coordinates of the places, as they’re not yet linked to suitable data sources.
Winding Down
With DM2E coming to an end, this is also the final blog post for this project on this blog; I’ll report on further updates on my personal blog. I’d like to thank the DM2E project for giving me the award, which has made it possible to make some important steps toward opening up historical research data. I’d also like to thank Magnus and his team for doing the “heavy lifting” in this project.