Last week the DM2E team at the Austrian National Library (ONB) organised a seminar on the wider possibilities of scholarly and library (re-)use of Linked Open Data in Vienna. Max Kaiser, Head of the Research & Development department of the ONB opened the afternoon and stressed how satisfied the library is with the progress that DM2E has made in the last years, both in aggregating manuscript content into Europeana as well as in publishing delivered metadata as Linked Open Data using the DM2E model, a specialised version of the Europeana Data Model (EDM) for the manuscript domain.
After this welcome, Doron Goldfarb (ONB) gave an introduction to the DM2E project and the four main areas of work: aggregation of manuscript metadata and content, interoperability infrastructure, digital humanities applications and community building.
Marko Knepper of the University Library of Frankfurt am Main then went on to explain, with examples from his library’s manuscripts, how library data is transformed into linked data through the use of tools developed in DM2E such as MINT and Pubby, showing the final result as it appears in the Europeana portal at the end.
After the first break, Bernhard Haslhofer (Open Knowledge Austria / AIT) and Lieke Ploeger (Open Knowledge) gave a joint presentation on the value of open data and the OpenGLAM network. Bernhard introduced the topic with a talk on his experiences with Maphub, an application he built which operates on open cultural heritage data and allows users to annotate digitized historical maps. Following on his example, Lieke introduced the OpenGLAM network, a global network of people working on opening up cultural data that was set up in the scope of the DM2E project, and talked about the recent and future activities of the OpenGLAM community.
Next up was Kristin Dill (ONB) with a presentation on the scholarly activities in DM2E. She talked about the Scholarly Domain Model (SDM), which informs the work on digital tools for humanities scholars by addressing gaps in digital workflows and recognising patterns in the behaviour of scholars. She showed the different layers of abstraction of the model, and demonstrated how certain scholarly activities can be identified in the Pundit tool.
The final talk of the day came from Susanne Müller of the EUROCORR project. After a brief introduction to the BurckhardtSource project, she detailed how the semantic annotation tools developed in DM2E have been applied to the European correspondence to Jakob Burckhardt, a Swiss cultural historian from the 19th century to enrich this data.
The last part of the day was reserved for a workshop based around the Pundit tool for semantic annotation from NET7. After an introduction to the tool, the group was divided into two for a hands-on session, which was received very well by participants.
Europäische Friedensverträge der Vormoderne online (“Early Modern European Peace Treaties Online”) is a comprehensive collection of about 1,800 bilateral and multilateral European peace treaties from the period of 1450 to 1789, published as an open access resource by the Leibniz Institute of European History (IEG). The goal of the project funded by the DM2E-funded Open Humanities Award is to publish the treaties metadata as Linked Open Data, and to evaluate the use of nanopublications as a representation format for humanities data.
We’ve now converted the the structured metadata from the legacy database into RDF. In my last post I talked a bit about the structure and content of the legacy database; as we expected, the conversion required a fair bit of interpretation and cleanup work, but all in all, it worked quite well.
As the basis for our data model we have, not surprisingly, used the DM2E model. Currently we have three main classes of entities, namely the treaties, the treaty partners (or signatories–but we prefer the term partner to avoid confusion with the negotiators, i.e., the persons who actually signed the treaties), and finally, the locations where the treaties were signed. We usedm2e:Manuscript as class for the treaties, edm:Agent as class for the partners, and edm:Place as class for the locations. Furthermore we use the following properties:
dc:title for the treaty titles,
dc:date for the treaty date,
edm:happenedAt for linking to the location,
rdfs:label for the names of partners and locations, and
skos:narrower and skos:broader for modeling the hierarchy of partners.
The last point may need some explanation. Partners may be in a hierarchical relationship to each other to model that a power may be part of a larger entity. For example, Austria was a part of the Holy Roman Empire, whereas Milan, Mantova, and Sardinia were (at various points in time) parts of Austria. However, historical realities tend to be quite messy, so these relations are not necessarily “part-of” relations in the strict sense; for example, Austria also had territories outside the Empire. The hierarchy also contains “fictitious partners” as a help for searching; for example, introducing Switzerland or Parts of the Empire as “fictitious partners” makes it easier to search for treaties concerning certain regions of Europe. This pragmatic approach was taken over from the legacy database, as we think it makes sense, at least for the time being.
To link the treaties to the treaty partners we’re currently using the dc:contributor property. We’re not yet completely happy with this solution; it seems to stretch the meaning of “contributor” a bit. Coming up with a better solution (or for arguments in favor of keeping dc:contributor!) is on our todo list.
So, if we take a specific treaty, such as the Provisional convention of subsidy between Great Britain, the States General, and Austria, we have the following data:
This display is somewhat simplified for illustration but should give you an idea. We have loaded the data into Fuseki and set up Pubby (a Linked Data frontend for SPARQL endpoints) on an internal server. For reference, Figure 1 shows the last page of the treaty; the last sentence before the seals and signatures gives the place and the date: Fait à La Haye le trente un du Mois d’Aout de l’année mille Sept cent quarante Six.
Figure 1: Provisional convention of subsidy between Great Britain, the States General, and Austria (Nationaal Archief, Den Haag, Staten-Generaal, nummer toegang 1.01.02, inventarisnummer 12597.187)
What are the next steps? Now that the data can be easily browsed through Pubby, of course you spot various smaller errors here and there, which we’re fixing as we go. More importantly, we are currently working on linking the locations and partners to suitable authority files, most notably the GND, which will make the data not just open but also linked. The locations should be relatively straightforward, but the partners may pose some problems; we take the obvious approach to first handle the easy cases and then deal with the rest.
The research group “Wittgenstein in Co-Text” is working on extending the FinderApp WiTTFind tool, which is currently used for exploring and researching Wittgenstein’s Big Typescript TS-213 (BT), to the rest of the 5000 pages of Wittgenstein’s Nachlass that are made freely available by the Wittgenstein Archives at the University of Bergen and are used as linked data software from the DM2E project. In October, they concentrated with full power on switching to professional open-source software development tools, the virtualization of the FinderApp to open it to other projects and the submission of a paper and poster on the work to a Digital Humanities conference in 2015.
Switching to professional open-source Software Development Tools
The aims in our award project, enlarging and opening our FinderApp WiTTFind to new fields of Digital Humanities, led to the decision that we have to switch from our svn-based “personal software development” to a more powerful distributed revision control and source code management system. Our decision fell on GIT, an open source software tool which proved excellent capabilities during the development of new Linux Kernels. We built up a GIT-Server at our institute and developed, collected and maintained all modules around our FinderApp under the roof of the GIT-group WAST (Wittgenstein Advanced Search Tools). Together with new storage and revision control, we extended our software development with additional tools like: Test Driven Development (TDD), Continuous Integration (CI) and integrated Build System (gitlabci), Continuous Delivery and Deployment, best-practices bug reporting, Build and Test Engineering and at last also Quality Assurance. Within the GIT-group WAST, every module is implemented as an own project, connected to responsible owners. A central WEB-based Feedback-Application was implemented, to enable email- and GIT-based postage for staging errors, problems and new feature requests. All the delivered issues are visible to the GIT-members of the WASTgroup. The Feedback-Application is widely used: 192 issues have been processed since the installation.
Restructuring and integration our AWARD-Project under GIT Control
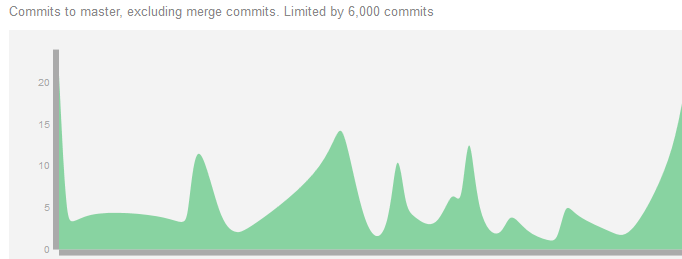
The modularization and restructuring of our programs and data around WiTTFind is finished and managed in the GIT-LAB group WAST. From now on, all data management and documentation is done under GIT-Control (see picture 1). An automatic quality assurance system is implemented to enable automatic testing of new software developments. Software will only be accepted and integrated as WAST-tool if there are automatic tests and they succeed. The project is maintained via the Feedback-Application.
Picture 1: Commit over time to WAST-git
New logo for Wittgenstein Advanced Search Tools (WAST)
To express the corporate identity we developed a new logo for our FinderApp WiTTFind, which is contained in the WAST-Tools. We extracted word-snippets from facsimiles of Ludwig Wittgenstein’s Nachlass:
Picture 2: WAST- Project LOGO
FinderApp for other Digital Humanity Projects
One of the biggest aims of our award project is to open our FinderApp WiTTFind and WAST-Tools to other Digital Humanities projects. The whole software should run interoperable under Linux, MacOS and Windows. To overcome the widespread software requirements of our application, which differ heavily between different platforms and even different releases, we use the virtualization software Docker. This technology, available open source for various operating systems, collects all software needed in one “container” and makes it run under docker-sever-control. In October we have released our first docker-container, which runs our FinderApp and WAST-Tools virtualized on laptops under Linux and soon MacOS as well. All our programmers in the project group use this technology to develop their software.
Picture 3: Interoperable Virtualized WiTTFind
Paper and poster for the Conference “Digital Humanities im deutschsprachigen Raum”, Graz 2015
To make our Wittgenstein Advanced Search Tools and the FinderApp WiTTFind known to a broader community in the field of Digital Humanities we submitted a paper and poster to the conference Digital Humanities im deutschsprachigen Raum (25-27 February 201, Graz, Austria). The paper “Wittgensteins Nachlass: Erkenntnisse und Weiterentwicklung der FinderApp WiTTFind” (authors Max Hadersbeck, Alois Pichler, Florian Fink, Daniel Bruder and Ina Arends) describes in great detail the latest developments of our project, while the poster “Wittgensteins Nachlass: Aufbau und Demonstration der FinderApp WiTTFind und ihrer Komponenten” (authors Yuliya Kalasouskaya, Matthias Lindinger, Stefan Schweter and Roman Capsamun) complements a live-demo of WiTTFind.
Enabling humanities research in the Linked Open Web – DM2E final event
Since the project start in February 2012, the partners in the DM2E project have been working on building the tools and communities to enable humanities researchers to work with manuscripts in the Linked Open Web. Before the project closes, in February 2015, we organise a final event to show and demonstrate the progress that has been achieved as well as to inspire future research in the area of Linked Open Data.
The day will include a keynote talk by Sally Chambers (DARIAH-EU / Göttingen Centre for Digital Humanities) on future sustainable digital services for humanities research communities in Europe, presentations and demonstrations of the final DM2E results from all work packages as well as talks by the winners of the second round of the Open Humanities Awards on the results of their projects.
Attendance is free but places are limited: join us to find out more about the DM2E final results!
Date and time: Thursday 11 December 2014, 10:00 – 17:00
Programme: the full agenda is also available for download here
10.00
Welcome and short introduction to DM2E (Violeta Trkulja – Humboldt University)
10:20
Keynote : Beyond DM2E: towards sustainable digital services for humanities research communities in Europe?
(Sally Chambers – DARIAH-EU, Göttingen Centre for Digital Humanities)
10:50
Europeana and the relevance of the DM2E results (Antoine Isaac – Europeana)
11:10
Coffee break
11:40
DM2E Content (Doron Goldfarb – ONB Austrian National Library)
12:10
Open Humanities Awards Open track: Early Modern European Peace Treaties Online (Michael Piotrowski – IEG Leibniz Institute of European History)
12:30
DM2E Interoperability infrastructure (Kai Eckert – University of Mannheim)
13:00
Lunch break
14.00
Open Humanities Awards Open track: SEA CHANGE (Rainer Simon – AIT Austrian Institute of Technology)
14:20
DM2E Digital Humanities research and engineering (with talks by Christian Morbidoni – Università Politecnica delle Marche / Net7, Steffen Hennicke – Humboldt Universität and Alessio Piccioli – Net7)
15:10
Open Humanities Awards DM2E track: finderapp WITTfind (Maximilian Hadersbeck – LMU University of Munich
15:30
Coffee break
16:00
DM2E Community building (Lieke Ploeger – Open Knowledge)
16:30
Closing words followed by drinks reception
Registration
Attendance is free but places are limited: please sign up through Eventbrite in case you plan to attend.
Bringing About the SEA CHANGE: Results from our 1st Workshop
About a week ago, on Friday October 31, we held our first annotation workshop for the SEA CHANGE project. As you may recall, SEA CHANGE will hold two such workshops. The workshop participants assemble in an informal setting to mark up geographical references in ancient texts and maps, and explore further how this data can deepen our understanding of these documents. The Heidelberg University Institute of Geography has kindly agreed to be our host for this first event. A big thank you goes to Lukas Loos for setting up our visit and taking care of local organization, and to Armin Volkmann for his spontaneous decision to merge his geo-archaeology seminar with our workshop on that day.
Morning Session – Let’s Annotate!
Leif, Pau and I started the day by briefly introducing the Pelagios project – which the SEA CHANGE results will feed into – to our 27 participants. Then, without further ado, everyone got to work with our Pelagios geo-annotation tool RECOGITO. RECOGITO has several “editing areas”, dedicated to different phases of the geo-annotation workflow:
An image annotation area to mark up and transcribe place names on map and manuscript scans
A text annotation area to tag place names in digital text
A geo-resolution area, where the identified (and transcribed) place names are mapped to gazetteer records (and thus, geographical coordinates)
Our participants hard at work
Recogito includes a range of relevant geographical documents from the Classical Latin and European Medieval Period, and participants were free to choose which ones they wanted to work on.
We are blown away by the results! Here are some numbers:
In total, participants made 6.620 contributions in the morning session. Four participants even made it into our all-time top-10 list! Which means they managed to make more than 645 contributions on that morning. (We’re impressed!)
People worked on 51 different documents: 19 text documents (8 out of which in Latin language!), and 32 map scans.
Looking a bit closer at what those 6.620 contributions were: they consisted of approximately 2.650 place name
identifications in text, 2.500 place name identifications on maps, 830 map transcriptions, 140 gazetteer resolutions and about 490 other actions, such as corrections, deletions or comments.
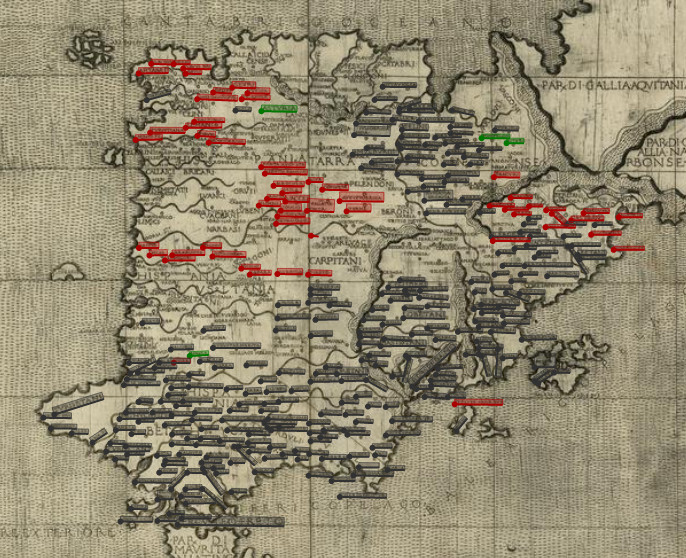
A well-tagged map of 15th Century Spain. Red tags indicate place names that still need transcribing.
A few random observations from our side:
Participants seemed to genuinely enjoy the process. Not only did we get positive feedback after the session, but several participants also followed our invitiation to get permanent Recogito logins so that they can continue contributing after the workshop. We saw a further 1.648 contributions on Saturday, November 1st, the day after workshop (and nation-wide Halloween parties, for that matter 😉
It was interesting for us to get such clear numbers with regard to the different types of contributions. On the one hand, these reflect how different phases of the annotation workflow are more or less time consuming. E.g. tagging a place name in a text is usually a matter of a double click, whereas on a map it takes a while to navigate the image and select the area (selecting is a process that involves a mouse click, drag, and another click). Hence the roughly equal number of name identifications in texts and maps, despite the fact that more people were working on maps. Transcribing, obviously, takes even more time, as does gazetteer resolution.
With regard to gazetteer resolution, we’re currently in the process of completely re-designing the user interface for this. We should have the new interface ready by the time of the next workshop. It will be interesting to see whether this will have an impact on our numbers.
Needless to say that this was, so far, the most active day we (and our Recogito server) has ever seen, almost tripling our previous daily record of September 15, with 2.312 contributions. We’re excited!
Afternoon Session – Let’s Explore!
In the afternoon session, Leif walked the audience through a brief tutorial on how to download data from Recogito and analyse it further in QGIS, an open source Geographical Information System. Not long after that, our participants were deeply engaged in exploring Medieval travel documents such as the Bordeaux Itinerary, matching e.g. the rate of stops and their different types against a 3D terrain model, and pondering about the time taken – and the hardships endured – by travellers in the 4th century AD during their journeys.
Participants exploring their data embedded in a 3D terrain model.
We would like to say a big Thank You! to everyone who was there, and made this such a big success. In case you were not there, though: don’t worry, there are still ways you can participate.
First, you can – as always – download all our data right from Recogito. Don’t be a stranger! No registration required. Grab our annotations. They are CC0 licensed, and packaged as CSV tables (the most straightforward data format when it comes to re-use, we think). Go ahead, experiment, and if you come up with something cool – be sure to let us know!
Last but not least: although annotating is, of course, much more fun when done together, you can also join our growing crowd of Recogito contributors online. Check our Beginner’s Tutorial. Drop us a line. We’re looking forward to hearing from you.
One aim of our project was to extend our FinderApp WiTTFind, which is currently used for exploring and researching only Ludwig Wittgenstein’s Big Typescript TS-213 (BT), to the rest of the 5000 pages of Wittgenstein’s Nachlass that are made freely available by the Wittgenstein Archives at the University of Bergen and are used as linked data software from the DM2E project. With the money from the award, we could engage three new members in our research group “Wittgenstein in Co-Text”: Roman Capsamun, Yuliya Kalasouskaya and Stefan Schweter.
To get an a good insight in the actual work of the Archive, the Bergen Electronic Edition (BEE) and the open-available parts of Wittgenstein’s Nachlass, two members of our research group, Angela Krey und Matthias Lindinger, traveled to the Wittgenstein Archive in Bergen. Together with Dr. Alois Pichler and Øyvind Liland Gjesdal (University of Bergen Library) they discussed the latest developments at the archive and transferred the rest of the 5000 pages from the Nachlass of Ludwig Wittgenstein to our institute. At the Bergen archive they also discussed the high density (HD) scanning of the complete Wittgenstein Nachlass, which is done in cooperation with Trinity College, Cambridge. During their visit they could join lessons of Prof. Dr. Peter Hacker, a famous Wittgenstein researchers. He was on a visit at the archive and spoke about „Philosophy and Neuroscience“ and „The Nature of Consciousness“. After the speeches, they could present him a demo of our FinderApp WiTTFind, which impressed him very much.
University of Bergen, Department of Philosophy, which houses the Wittgenstein Archives
Finished Milestones in our Award project in September 2014 include:
Extending the Nachlass-data for our FinderApp WiTTFind
We transferred the rest of all 5000 Pages of the free available part of Wittgenstein’s Nachlass into our storage-area at our institute. One problem of the XML-TEI-P5 compatible edition data in Bergen is, that they defined XML-tags with a lot of information, which is not important for our FinderApp. So we defined a restricted, limited XML-TEI-P5 compatible tagset which includes all information which is necessary for our FinderApp. We call this tagset: “CISWAB-tagset”. To reduce the Bergen-tagset to our CISWAB-tagset we programmed XSLT-scripts together with our cooperation-partner in Bergen. To validate the CISWAB-tagset data, we defined an XML-DTD-scheme (CISWAB-DTD).
Extending the syntactic disambiguation of the Nachlass-Data
To extend syntactic disambiguation to the rest of the 5000 pages we had to program new scripts, which runs the Part of Speech (POS) tagging stage with the “treetagger” automatically. Every new incoming CISWAB-XML file is automatically tagged and inserted in the storage-area of our FinderApp.
Using “Tesseract” for OCR and switching to HD-scans for our WiTTReader
One central part of our FinderApp is the facsimile reader WiTTReader which allows to display, browse and highlight all the found hits of the Finder within the original facsimile. Up to now we used only single density (SD) facsimile to scroll through the Nachlass. In the next generation of our FinderApp we want to use high density (HD) facsimile, which are currently produced at the Trinity College in Cambridge.
As it is very important in our project, to use only open source tools, we won’t use the OCR tool ABBYY-finereader (version 11) anymore. After some tests, we decided to use “Tesseract” which is also used by the Google Books project. We transferred the first HD-facsimile of the Nachlass to our institute and the first OCR-quality-tests with “Tesseract” are very promising.
Putting Linked Library Data to Work: the DM2E Showcase
Join us on Tuesday 18 November at the ONB Austrian National Library in Vienna to find out more about the DM2E project and the wider possibilities of scholarly and library (re-)use of Linked Open Data.
In this half-day seminar we will share information on how content has been used for mappings to Europeana and for publishing delivered metadata as Linked Open Data using the DM2E model, a specialised version of the Europeana Data Model (EDM) for the manuscript domain. In addition, Open Knowledge will be present to talk about the value of open data and the OpenGLAM network and we will show results of the work carried out by Digital Humanities scholars applying the semantic annotation tools developed in DM2E to a subset of the published content. The day will be concluded with a workshop based around the Pundit tool for semantic annotation from NET7.
Date and time: Tuesday, 18 November 2014, 13:00 – 18:00
Location: Oratorium, Austrian National Library, Josefsplatz 1, 1015 Vienna, Austria
Programme: the full agenda is also available for download here
13.00
Max Kaiser, ONB Austrian National Library: Welcome
13:15
Doron Goldfarb, ONB Austrian National Library: Introduction to the DM2E project
13:45
Marko Knepper, University Library Frankfurt am Main: From Library Data to Linked Open Data
14:15
Coffee break
14:30
Bernhard Haslhofer, Open Knowledge Austria and Lieke Ploeger, Open Knowledge: The value of open data and the OpenGLAM network
15:00
Kristin Dill, ONB Austrian National Library: DM2E and Scholarly Activities
Alessio Piccoli, Net7 and Christian Morbidoni, Università Politecnica delle Marche: Semantic annotation with Pundit: Hands on session
* a laptop is required to take part in the hands on session
18:00
End
Registration:
Attendance is free but places are limited: please sign up through Eventbrite in case you plan to attend our seminar.
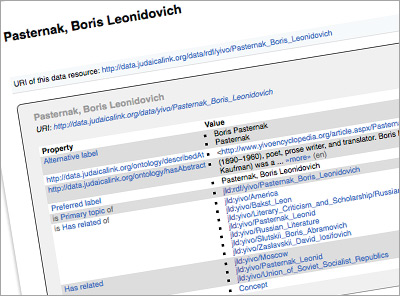
The DM2E project has provided the inspiration for two of its partners ― Dr Kai Eckert of the University of Mannheim and Dov Winer of the European Association for Jewish Culture and Judaica Europeana ― to embark on an initiative to publish existing reference works on Jewish history and culture as Linked Data under the name JudaicaLink.
Reference works such as encyclopedias, glossaries, thesauries or catalogues function as guides to a scholarly domain as well as anchor points and manifestations of scholarly work. On the web of Linked Data, they can perform a key function of interlinking resources related to the described concepts. In effect, this means they can be enriched by creating new links between and within different encyclopedias. This function could revolutionize the work of digital humanists’ and become the bread and butter of their research diet.
To our almost certain knowledge JudaicaLink is the first such initiative and platform in the field of Jewish studies.
JudaicaLink: a plaform for access to Linked Data versions of encyclopedias
Like with many pioneering LOD publishing efforts, the first challenge was to persuade the publishers and maintainers of such reference works to give their permission to create a Linked Data version of their encyclopedia and publish it on JudaicaLink.org. Provided the work is already online, the minimal requirement is that the URLs of the articles in the encyclopedia remain stable. It is also possible to publish an LOD version of a given work on the publishers own website provided they have the technical infrastructure and capacity to do so. In this case, JudaicaLink can provide information and a central search functionality.
The YIVO Encyclopedia of Jews in Eastern Europe
We have been fortunate that after some discussion the leaders of the YIVO Institute for Jewish Research in New York saw the potential of LOD for their extraordinary YIVO Encyclopedia of Jews in Eastern Europe and gave us the go ahead. From the point of view of a Linked Data enthusiast, the YIVO Encyclopedia is really a great resource. All articles are highly interlinked, often they even provide a hierarchy of sub-concepts described under a superordinate concept. Links to glossary terms provide further terminological control.
An example of topic headings from the YIVO Encyclopedia of Jews in Eastern Europe published in a LOD format
Encyclopedia of Russian Jewry
Recently, JudaicaLink announced also the first release of the Encyclopedia of Russian Jewry (Rujen), published in Moscow since 1994, as Linked Open Data. Rujen is not as interlinked as YIVO and the articles are much shorter on average, but it contains many more articles (about 20,000 compared to about 2,500 YIVO articles). The first obvious feature of Rujen for English-speaking people is the language: it’s Russian. The Cyrillic alphabet raises an important question regarding Linked Data: how to coin the URIs for the articles. We are still considering different solutions. Basically, there are three options based on the actual identifier, the Cyrillic title of the article:
Use an Internationalized Resource Identifier, an IRI. For example: http://data.judaicalink.org/data/rujen/гатов_шапсель_гиршевич. This is perfectly readable (at least by Russians) and probably the option to be preferred. However, it is not clear if all applications support IRIs correctly and we would like to have the data as easily accessible as possible. Therefore, and also because we wanted to try it, we decided on the next option:
Use a transliterated URI. For example: http://data.judaicalink.org/data/rujen/gatov_shapselj_girshevich. Again, this is perfectly readable, and since Rujen is mostly about persons and locations, people familiar with the Latin alphabet can make sense of it. However, there are drawbacks. We did not transliterate just because of our widely shared ignorance of the Cyrillic alphabet. We adopted this option because we wanted to have valid URIs, for the sake of backwards-compatibility and technical interoperability. This means using only the 26 common Latin letters, no diacritics, no special characters. And the transliteration should be simple, based on a lookup-table that translates every Cyrillic letter consistently to one or more Latin characters. This is obviously not an ideal way to transliterate and, according to our tests with our nice colleagues from Belarus and Russia, it quite often produces somewhat strange results for native speakers. However, they assured us that it is still readable and not insulting.
Actually, there is also a fourth option that is completely different: using some kind of numbering or code scheme (for example a hash value of the title), but despite leading to shorter URIs, this again has the effect that no one can make sense of it, similar to option 1. There are people who advocate this approach precisely for this reason: a URI should not contain possibly misleading semantics. And, of course, a number does not show an arbitrary preference for a language or an alphabet.
So, we settled for transliteration as our first attempt, but we are curious about your ideas and opinion. After reading this long and hopefully interesting digression, you are probably much more interested in the question: how can I access this LOD resource?
The easiest way is the following: while browsing the YIVO Encyclopedia, you can access the data representation by simply replacing www.yivoencyclopedia.org/article.aspx/ with data.judaicalink.org/data/yivo/ in the URL field of the browser. For convenience, you can also use our bookmarklets. They are provided together with additional information for each encyclopedia here. Just drag and drop them to your bookmarks and when you click on this bookmark while on an encyclopedia article, you will be directed to the Linked Data version. For an even quicker look, you can also just start at the concept used above in option 3, or for YIVO, for example here: http://data.judaicalink.org/data/html/yivo/Abramovitsh_Sholem_Yankev.
All in all, JudaicaLink now provides access to 22,808 concepts in English (approx. 10%) and in Russian (approx. 90%), mostly locations and persons.
JudaicaLink gets links
From the beginning our vision was not only about the provision of stable URIs and data for concepts described in the encyclopedias. It was also about the generation of links between these resources and other linked data resources on the Web. In a first run, we used Silk to generate links between JudaicaLink and the following sources:
All the links have been created automatically and are primarily based on the labels of the resources, so some wrong links are to be expected. Nevertheless this is an important first step. For the present, we provide the links directly together with the resource descriptions (as owl:sameAs links), but we will separate them with proper identification of the provenance as soon as we are able to use more sophisticated linking approaches. One immediate benefit from this simple linking is that we could already generate links between both encyclopedias. This works because several sources, like DBpedia, are multilingual and therefore links to both encyclopedias could be established. Whenever a single resource has two links to one resource in each encyclopedia, an additional link establishing the identity of these two resources could be inferred.
JudaicaLink arrives in the Cloud
With all these links, JudaicaLink is now also part of the famous LOD Cloud that was released recently in its latest version. You can find us at about 4 o’clock, close to the border and right beside our neighbour project DM2E.
We hope the readers of this blog will spread the word and help us to convince more publishers to work with us. And do let us know what you think of JudaicaLink and what additional ideas you have. We look forward to hearing from you!
The Digital Humanities Advisory Board of the DM2E project meets on a regular basis to ensure that the research direction and technical developments within the project meet the needs of digital humanities scholars. On 2 October the Board held their fifth meeting, with the following attendees:
Dirk Wintergrün (Max-Planck-Institut für Wissenschaftsgeschichte)
Sally Chambers (DARIAH, Göttingen Centre for the Digital Humanities)
Laurent Romary (INRIA)
Alois Pichler (University of Bergen)
Alastair Dunning (The European Library)
At the start of the meeting, Christian Morbidoni (Net7) presented the latest developments of Pundit 2 and its new features, which include an improved usability interface and added flexibility, which now makes it easier to adopt Pundit for specific needs such as user experiments.
Steffen Hennicke (Humboldt-Universität zu Berlin) then went on to present the user experiments that are currently ongoing with Pundit2 and the new version of Korbo. The first set of experiments focuses more generally on how humanists work with Pundit and Linked Data: students from fields such as Archival Sciences and (Educational) History formulated an original and relevant research question or interest, discussed the ontology in a first workshop and worked with Pundit on annotating specific material, with a second workshop to talk through their results.
The goal of the second set of experiments is to better understand the reasoning process of digital humanists working with Linked Data. Three different users (a philosopher, an art historian and an historian) were asked to formulate an original and relevant research question pertaining to their particular set of research objects and data and to find an answer to this question using a faceted browser containing and visualising their data. During this work they self-document their work and thought process.
Both sets of experiments are still work in progress: the results will be presented at the final meeting of DM2E on 11 December in Pisa, Italy, together with the final results of the DM2E project and those of the winners of the Open Humanities Awards.
Attendance to this event is free and registration will open soon, if you are interested in coming, please save the date and keep an eye out on the DM2E blog.
The event is focused on digital humanists and intended to target research-driven experimentation with existing humanities data sets. One of the most exciting recent developments in digital humanities include the investigation and analysis of complex data sets that require the close collaboration between Humanities and computing researchers. The aim of the hack day is not to produce complete applications but to experiment with methods and technologies to investigate these data sets so that at the end we can have an understanding of the types of novel techniques that are emerging.
Possible themes include but are not limited to
Research in textual annotation has been a particular strength of digital humanities. Where are the next frontiers? How can we bring together insights from other fields and digital humanities?
How do we provide linking and sharing humanities data that makes sense of its complex structure, with many internal relationships both structural and semantic. In particular, distributed Humanities research data often includes digital material combining objects in multiple media, and in addition there is diversity of standards for describing the data.
Visualisation. How do we develop reasonable visualisations that are practical and help build on overall intuition for the underlying humanities data set
How can we advance the novel humanities technique of network analysis to describe complex relationships of ‘things’ in social-historical systems: people, places, etc.
With this hack day we seek to form groups of computing and humanities researchers that will work together to come up with small-scale prototypes that showcase new and novel ways of working with humanities data.
Date: Friday 28 November 2014 Time: 9.00 – 19.00 Location: Small Committee Room (K0.31), King’s College Building, Strand Campus, London – How to get there Sign up: Attendance is free but places are limited: please fill in the sign-up form to register.
For an impression of the first Humanities Hack event, please check this blog report.





 Date and time: Thursday 11 December 2014, 10:00 – 17:00
Date and time: Thursday 11 December 2014, 10:00 – 17:00





{kind=link}
{kind=link}