*This is the fourth in a series of posts from Dr Maximilian Hadersbeck, the recipient of the DM2E Open Humanities Awards – DM2E track.*
The research group “Wittgenstein in Co-Text” is working on extending the FinderApp WiTTFind tool, which is currently used for exploring and researching Wittgenstein’s Big Typescript TS-213 (BT), to the rest of the 5000 pages of Wittgenstein’s Nachlass that are made freely available by the Wittgenstein Archives at the University of Bergen and are used as linked data software from the DM2E project. The work in December focused on the implementation of new features in WiTTFind, extensive work for the PISA-Demo Milestone, the speech and presentation at the DM2E final event on 11 December in Pisa and following discussions.
Extensive work for our PISA-Demo Milestone
We continued to strengthen out gitlab and docker environment to reach our aim of producing a high quality FinderApp for Digital Humanity projects running under different operating-systems. For our presentation in Pisa we defined a PISA-Demo milestone which introduced new features, defined in 27 issues like: setting permanent webpage configuration-values; redesign webpage with bootstrap and adding multi-doc behavior; new logo and header line; adding scrollbar to our webpage; sort display of hits; switching to HD-facsimile; adapting the facsimile-reader to HD-facsimile; rewriting help-page and new E2E tests. To show the extensive software-activities we did in our gitlab short before the PISA-Demo Milestone, see figures 1, 2 and 3.
Speech and Demonstration of our FinderAPP at DM2E final event, 11.12.2014, Pisa
One aim of our award project was to give a speech and a demo at the DM2E Final event in Pisa. Our speech had the title: “Open Humanities Awards DM2E track: FinderApp WiTTFind, Wittgensteins Nachlass: Computational linguistics and philosophy” and the authors where Max Hadersbeck, Roman Capsamun, Yuliya Kalasouskaya, Stefan Schweter from the Centrum für Informations- und Sprachverarbeitung (CIS), LMU, München.
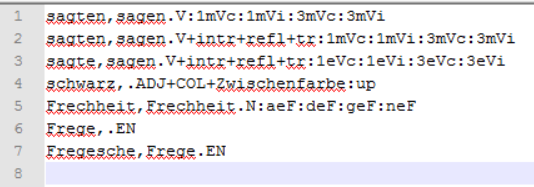
In our speech we first gave a short overview of Ludwig Wittgenstein‘s Nachlass and available texts for our FinderApp. Then we described, what kind of “fine-grained computational linguistic perspectives on editions” our Finder WiTTFind offers. We showed the open source aspects of our software and demonstrated the tools. After this we stepped into the details of our implementations: The rule based access to the data together with local grammars. We showed the differences of our rule-based tool, compared to statistical indexing search machines like google books, Open Library project and apache Solr. We gave a short insight into one basis of our tool, our digital full-form lexicon of Wittgenstein’s Nachlass with 46000 entries (see figure 4 The Digital Lexicon WiTTLex)
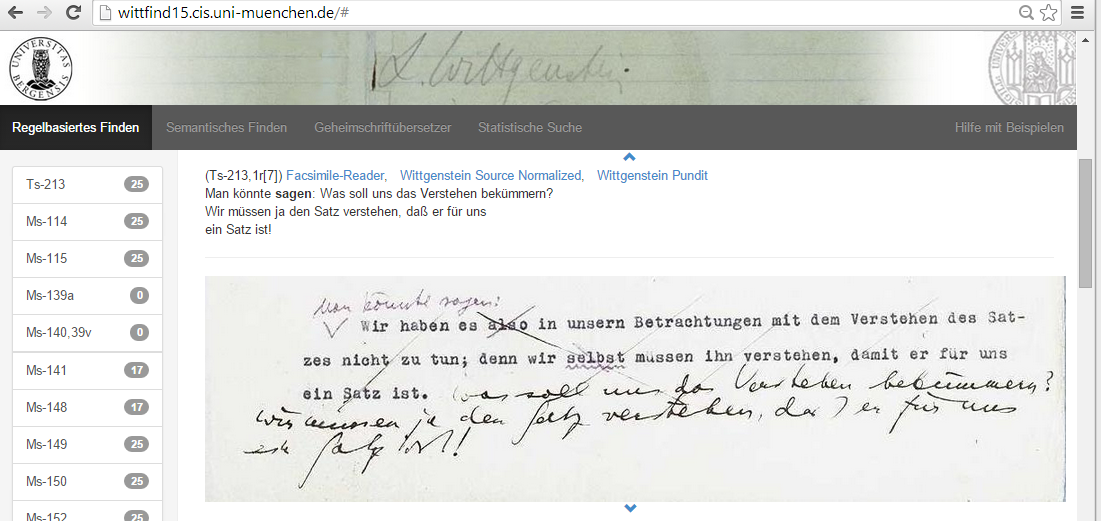
In the next part of our speech, we informed the attendees about other important aims of our project, like extending data to 5000 pages of Wittgenstein’s Nachlass and making our finder openly available to other digital humanity projects by defining APIs and a XML-TEI-P5 tagset. We presented OCR tools for facsimile-integration and a facsimile-reader for the new multidoc environment. The last aim of our project was, that our software should work as an interoperable distributed application (Linux, Macos, Windows) and it should be browser and device independent. We reached this aim by using gitlab, docker and bootstrap software. In the final part of our speech we presented our new multidoc browser frontend (see figure 2).
Discussion after the speech in Pisa
After our speech and at the evening-meeting we had very interesting discussions with the DM2E partners about our rule-based and not statistically access of our FinderApp to the Wittgenstein Nachlass. We showed that the rule-based access works perfect on limited data, like we have here, because with the help of rules (local grammars) we can make a lot of disambiguations in the field of semantics and syntax. The second remarkable point in the discussions were oberservations within the cooperation work with “Humanity”-researchers, in our case philosophers. We found the phenomenon that the philosophers fully accept and use only tools, if they find their specific scientific-language and categories present and if the search tool offers almost 100% precision and 100% recall. We admit, that these limits can never be reached, but what is the important: “Humanists” are not interested in sophisticated programming tricks and features, which computer-scientists love so much, they expect solid and clear algorithms behind finding the sentences around their specified word-phrases. They also expect interactive menus with fine grained setting possibilities, to investigate and influence the way of finding the specific text, which fits to their question.
Comments are closed.