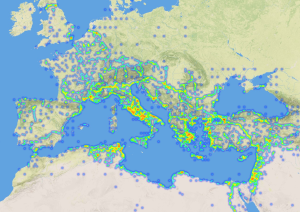
SEA CHANGE aims to facilitate the mass annotation of places in Historic Geospatial Documents (both geographic texts and maps) in two hackathon-style annotation workshops. We are pleased to announce that the first of these workshops will take place at the University of Heidelberg, on October 30-31. Our special thanks go to Lukas Loos from the Institute of Geography who has kindly offered to be our host for this event.
SEA CHANGE is part of the Pelagios project, an extensive network that is interlinking annotated online resources that document the past. The results from SEA CHANGE will feed back into Pelagios, making our interlinked resources even richer and more extensive. In preparation, those of us at Pelagios have already been annotating a range of Greek literary texts with a specific geographic focus, and have compiled a candidate list of documents from the European Middle Ages to work with next. On the technical side, we have extended our digital toolbox to allow us to annotate high-resolution imagery.
We’ve prepared a little sneak preview in the screencast above. The real thing will make its first live & hands-on appearance at the workshop. In case you happen to be around, and your curiosity is piqued, you are welcome to join us, subject to space & availability. If you are interested, then do drop us a line – first come, first serve!
In the first part of the session we introduced the audience to the principles of semantic annotation making a short presentation of the main features of the Pundit software and its components.
In the second part of the session community, we carried out some practical exercises. The People Time Person (PTP) experiment allows users to annotate snippets of text expressing the concept that a person has been in a certain place at a certain time. The Annomatic experiment allows users to create annotations semi-automatically. After creating annotations some visualization tools have been used in order to display the “knowledge” created during the experiment. The following website has been used to facilitate the experiment conduction http://dev.thepund.it/dariah2014/
At the end of the experiments we asked participants, who were about 30, to complete a questionnaire to gather their feedback.
Since the project start in February 2012, the partners in the DM2E project have been working on opening up prominent manuscripts and developing open workflows for migration of this data to Europeana and the wider Linked Open Web. Before the project closes, in February 2015, the consortium is organising a final series of events to demonstrate the progress that has been achieved as well as to inspire future research in the area of Linked Open Data. Join us at one of the following events to hear more!
18 November 2014: Putting Linked Library Data to Work: the DM2E Showcase (ONB Austrian National Library, Vienna, Austria)
This half-day seminar (taking place from 13.00 – 18.00) will be divided into two parts. In the first part we focus on the work of the content providing partners from the DM2E project. We will share information on how the providers’ content has been used for mappings to Europeana and for publishing delivered metadata as Linked Open Data using the DM2E model, a specialised version of the Europeana Data Model (EDM) for the manuscript domain. In addition, Open Knowledge will be present to talk about the value of open data and the OpenGLAM network.
The second part will focus on possibilities of scholarly (re-)use of Linked Open Data. Among other topics, it will present the results of the work carried out by Digital Humanities scholars applying the semantic annotation tools developed in DM2E to a subset of the published content. The day will be concluded with a workshop based around the Pundit tool for semantic annotation from NET7.
1-3 December 2014: workshop ‘RDF Application Profiles in Cultural Heritage’ at the SWIB2014 Semantic Web in Libraries conference (Bonn, Germany)
The SWIB conference aims to provide substantial information on Linked Open Data developments relevant to the library world and to foster the exchange of ideas and experiences among practitioners. SWIB encourages thinking outside the box by involving participants and speakers from other domains, such as scholarly communications, museums and archives, or related industries.
DM2E is organising a workshop at this conference together with Europeana and the DCMI RDF Application Profiles Task Group (RDF-AP) on the definition, creation and use of application profiles, with the DM2E model as one of the case studies. Registration for the conference has already opened: the full programme and more information on this workshop is available here.
11 December 2014: DM2E final event (Pisa, Italy)
Towards the closing of our project, we invite all those interested to come to Pisa for the presentation of our final results. Speakers from the DM2E consortium will demonstrate what has been achieved throughout the course of the project and how the tools and communities created have helped to further humanities research in the area of manuscripts in the Linked Open Web.
The winners of the second round of the Open Humanities Awards will be participating in this event as well and show the results of their projects. Finally, there will be a keynote talk from a prominent researcher from the digital humanities field.
More information on the programme for each of these events, as well as the registration details, will be announced through the DM2E website in the near future.
“Europäische Friedensverträge der Vormoderne online” (“Early Modern European Peace Treaties Online”) is a comprehensive collection of about 1,800 bilateral and multilateral European peace treaties from the period of 1450 to 1789, published as an open access resource by the Leibniz Institute of European History (IEG). Currently the metadata is stored in a relational database with a Web front-end. This project has two primary goals:
1. the publication of the treaties metadata as Linked Open Data, and
2. the evaluation of nanopublications as a representation format for humanities data.
The project got off to a rocky start, as I had massive troubles finding someone to work on it. The IEG is a non-university research institute, so I do not have ready access to students—and in particular not to students with knowledge about Linked Open Data (LOD). I was about to give up, when Magnus Pfeffer of the Stuttgart Media University called to tell me he’d be interested to work on it with his team. He’s got lots of experience with LOD, so I’m very happy to have him work with me on the project.
We’ve now started to work on the first goal, the publication of the treaties metadata as LOD. This should be a relatively straightforward process, whereas the second goal, the evaluation of the nanopublications approach, will be more experimental—obviously, since nobody has used it in such a context yet.
The process for converting the content of the existing database into LOD basically consists of four steps:
1. Analyzing the data. The existing database consists of 11 tables and numerous fields. Some of the fields have telling names, but not all of them. Another question will be what the fields actually contain; it seems that sometimes creative solutions have been used. For example, the parties of a treaty are stored in a field declared as follows:
`partners` varchar(255) NOT NULL DEFAULT ”
This is a string field, but the field doesn’t contain the names of the parties, but rather their IDs, for example:
‘37,46,253’
You can then look up the names in another table and find out that 37 is France, 46 is Genoa, and 253 is Naples-Sicily. This is a workaround for the problem of storing lists of variable length, which is quite tedious in a relational database. While this approach is clearly better than hardcoding the names of the parties in every record, it moves a part of the semantics into the application, which has to know that what looks like a string is actually a list of keys for a table.
Now, this example is not particularly complicated, but it illustrates that a thorough analysis of the database is necessary in order to accurately extract and convert the information it contains.
2. Identifying and selecting pertinent ontologies. We don’t want to re-invent the wheel but rather want to build upon existing and proven ontologies for describing the treaties. One idea we’ve discussed is to model them as events; one could then use an ontology like LODE. However, we will first need to see what information we need to represent, i.e., what we find in the database.
3. Modelling the information in RDF. Once we know how to conceptually model the information, we need to define how to actually represent the information on a treaty in RDF.
4. Generating the data. Finally, we can then iterate over the database, extract the information, combine it into RDF statements, and output them in a form we can then import into a triple store.
At this point, the basic data on the treaties will be available as LOD. However, some very interesting information is only available as unstructured text, for example the references to secondary literature or the names of the signees. At this point, we’ll probably get back to the database to see what additional information could be extracted—with reasonable effort—for inclusion.
Getting out the basic information should be straightforward, but, as always when dealing with legacy data, we may be in for some surprises…
On 17-19 September the DARIAH-EU network organises its fourth General VCC (Virtual Competency Centres) meeting in Rome. The DARIAH-EU infrastructure is focused on bringing together individual state-of-the-art digital Arts and Humanities activities across Europe. Their annual meeting provides opportunities to work together on topics within their Virtual Competency Centres (VCC) and to share experiences from various fields within the digital humanities.
This year, the DARIAH-EU general meeting will also guest specific community sessions alongside the general programme. We are happy to announce that DM2E has been selected to host a community session on the Pundit tool, the semantic annotation tool that is being developed as part of work package 3.
This community session, entitled Pundit, a semantic annotation tool for researchers will take place on Thursday 18 September. The session aims at illustrating Pundit main features and components (the client, Feed, Ask) as well as showing how it has been used by specific scholarly communities in Philosophy, History of Art, Philology and History of Thought domains. Moreover, attendees will be practically introduced to Pundit through dedicated exercises thought to give them the first skills to produce semantic annotations on Digital Libraries and generic websites.
Attendance to this event is free: registration is possible through Eventbrite.
Johann Gottfried Dingler, born 1778, was a German chemist and industrialist. He realised that the reporting on technological innovations was insufficient in his time. In 1820 he started to publish his “Polytechnisches Journal” on a monthly basis, which included scientific articles in the field of electrical technology, mining and chemical engineering, and the translation and discussions of European patent specifications. The journal is often referred to as “Dingler” and seen as a valuable resource:
“The journal was published over a period of 111 years and has hence became an important and European-wide source for the history of knowledge, culture, and technology — in Germany at least it is without compare” (Polytechnische Journal website).
The schema language used to describe the metadata is non modified TEI-P5 XML. The logical description of the records follows the recommendations of the TEI guidelines.
Background: The Metadata Format TEI
TEI stands for Text Encoding Initiative, which is a consortium for the contributed development of a standard metadata format for the representation of texts in digital form. The provided guidelines by the initiative are standard specifications for encoding methods for machine-readable texts. The TEI guidelines are widely used by libraries, museums, publishers and individual scholars to present texts for online research, teaching and preservation. The most recent version of the guidelines is TEI-P5.
The provided metadata for the mappings in DM2E came directly from the owner and creator of the records, the Institute for Cultural History and Theory. For the finalised version of the mapping to the DM2E model, DM2E got local copies of the last modified TEI-XML metadata records of the complete journal on volume and on article level.
The current mapping is based on the first test mappings which were carried out using the DM2E model v1.0 schema in MINT. Two different ore:Aggregation and edm:ProvidedCHO classes were created: one for a journal issue, another for a journal article. After the first mapping circle with MINT, which already included about two-thirds of the first mapping, further mapping steps were carried out by manually working on the MINT output (supported by the Oxygen editor). This was mainly done due to readability reasons (the output file was split up into different files for the creation of journal issues and articles), to reduce redundant steps in the mapping workflow (URIs of all classes were created as variables instead of typing them repeatedly) and to include steps that were not possible to proceed with MINT (e.g. normalising URIs or the creation of titles for smaller CHOs). Furthermore, the mappings were first created for the DM2E model v1.0 and then manually adapted to DM2E v1.1. It was much easier and faster to do this step by hand than by repeating the whole mapping in MINT.
The TEI data of the Dingler records are mapped on journal, issue, article and page level since almost all TEI documents encode full texts. Basic provider descriptive metadata from the TEI header is transformed in DM2E without any loss of data. Missing mandatory elements that the DM2E model requires are completed by default values.
Although all TEI-encoded full texts are based on philological methods, there are almost no semantically marked up persons, corporate bodies, or other subjects. In order to produce not only RDF literals, but URI references (resources), full text literals have to be transformed into URIs during the mapping or have to be extracted and processed by SILK in a second step, the contextualisation.
Representation of Hierarchical Levels
The TEI records include a representation of the hierarchical structure of the journal. The top-level is described within the TEI-header on article level and includes the basic metadata about the physical journal and about the online journal as well. The metadata on the journals is mapped to the top-level CHO, which is related to the sub-level-CHOs on the next level, the issues of the journal, via the dcterms:hasPart property. Issues include articles, which in turn gather CHOs on the lowest representational level in the object hierarchy: the pages. All top-down hierarchical relations are described by dcterms:hasPart and respectively with dcterms:isPartOf for all bottom-up relations, as these are inverse properties.
Figure 2 illustrates the hierarchical concept in the Dingler records. The linear relations between the resources on one level are defined with the property edm:IsNextInSequence as proposed in the Europeana Data Model specification.
Figure 2: Hierarchical concept in the Dingler records
Julia Iwanowa, Evelyn Dröge and Violeta Trkulja
Berlin School of Library and Information Science, Humboldt Universität zu Berlin
The metadata interoperability platform MINT (http://mint.image.ntua.gr) is implementing aggregation workflows in the Europeana ecosystem. It was first introduced in the ATHENA project, that made circa 4 million items available to Europeana between 2008 and 2011. Central development continued, along with customised versions that facilitated several initiatives in the domain, including EUscreen, ECLAP, CARARE, DCA, Linked Heritage, PartagePlus and 3D-Icons. MINT currently supports several projects in the Europeana ecosystem such as Europeana Photography, Europeana Fashion, AthenaPlus, LoCloud, EUscreenXL and Europeana Sounds. The MINT group also contributes in various infrastructure, technology and policy projects such as Europeana Connect, Indicate, Europeana Awareness, Europeana Creative, Ambrosia and Europeana Space. Finally, it is in the core of the Europeana ingestion infrastructure that implements their internal aggregation and publication workflow, while it has contributed in the starting up of the Digital Public Library of America, having succeeded in the respective beta sprint and invited to present in the first and second plenary meetings.
In DM2E, MINT and D2R were introduced in order to kick off the aggregation tasks, before the development of the workflow management component and the respective user interface by work package 2. A dedicated MINT instance was setup, implementing the XSD for the DM2E model, based on the National Technical University of Athens (NTUA)’s implementation of EDM for Europeana. Dedicated training workshops instructed providers in the use of the visual mapping editor for the XSLT language, in order to create test mappings for XML or CSV imports that had to be translated to RDF. The two RDFizer tools and the SILK framework for contextualisation consisted the initial version of the project’s interoperability infrastructure.
With the design of the intermediate version of the infrastructure, MINT’s REST API was extended to expose the platform’s data and services, using the ontology that was introduced in the web-based engine for the specification, composition and execution of workflows. MINT also implemented a preprocessing step that improved the handling of records serialised in the MARC format and the subsequent use of the visual mapping editor. The preview services were also improved with the addition of a Europeana portal preview for EDM and a graph visualisation for RDF instances of the DM2E model. In parallel, an evaluation process led by work package 1 aimed at identifying the benefits and shortcomings of MINT when used with the various input models ingested by DM2E providers. Particularly, users were asked to evaluate the four basic aggregation steps; import, mapping creation, validation and XSLT export.
MINT workspace – import
In general, MINT’s visual mapping functionality was accepted by the users. The concept was deemed very intuitive and helped users become familiar with the target data schema. The results of the evaluation pointed out that schemas which are not focused only at representing descriptive metadata, but also incorporate business processes or hierarchical representations of collections – such as EAD – are difficult to handle with the visual mapping editor, but could still benefit by creating a first version of the XSLT in MINT. Finally, users were able to identify some interesting aspects of working with that version of MINT that resulted in a set of bug fixes and improvements in the next release.
MINT workspace – mapping
With the adoption of the single sign-on solution (JOSSO), MINT is fully integrated in the DM2E infrastructure, allowing the use of the mapping editor from the browser-based user interface (OmNom). For the final version of the infrastructure, two more MINT services are reused in order to assist providers and the work package 1 content team with improving the quality of publication, the Europeana HTML preview and, the validation service for the EDM model that uses the XSD and schematron rules.
Overall, the development, integration and evaluation processes resulted in productive discussions, continuously fine-tuned requirements and the evolution of both MINT and the interoperability infrastructure towards stable, intuitive tools for the execution of aggregation workflows for digital cultural heritage objects in the realm of digitised manuscripts.
Nasos Drosopoulos
Senior Researcher, National Technical University of Athens
During May we invited humanities academics and technologists to submit innovative ideas for small technology projects that would further humanities research by either using open content, open data and/or open source (in the Open track) or building upon the research, tools and data developed within the DM2E project (in the DM2E track).
We’re very pleased to announce that the winners of this second round of the Open Humanities Awards are :
Open track
Dr. Rainer Simon (AIT Austrian Institute of Technology), Leif Isaksen & Pau de Soto Cañamares (University of Southampton) and Elton Barker (The Open University) for the project SEA CHANGE
Dr.-Ing. Michael Piotrowski (Leibniz Institute of European History (IEG)) for the project Early Modern European Peace Treaties Online
DM2E track
Dr. Maximilian Hadersbeck (Center for Information and Language Processing (CIS), University of Munich (LMU)) for the project finderApp WITTFind
All winners will receive financial support to help them undertake the work they proposed and will be blogging about the progress of their project. You can follow their progress via the [DM2E blog](https://dm2e.eu/blog).
—
####Open track – Award 1: SEA CHANGE
The first award of the Open track goes to Dr. Rainer Simon (AIT), Leif Isaksen & Pau de Soto Cañamares (University of Southampton) and Elton Barker (The Open University) for the project Socially Enhanced Annotation for Cartographic History And Narrative GEography (SEA CHANGE). This project will make available high-quality open geographic metadata for Historic Geospatial Documents – historic documents that use written or visual representation to describe geographic space. In the course of two “hackathon”-like workshops, the project will work with academics and students of relevant disciplines (e.g. history, geography) as well as with interested members of the public on annotating selected documents and making use of the results.
The outcome will be a body of Linked Open Data that enables humanities scholars to “map” and compare the narrative of ancient literary texts, and the contents of early cartographic sources with modern day tools like Web maps and GIS. This data will make it possible to contrast their geographic properties, toponymy and spatial relationships. Contributing to the wider ecosystem of the “Graph of Humanities Data” that is gathering pace in the Digital Humanities (linking data about people, places, events, canonical references, etc.), it will open up new avenues for computational and quantitative research in a variety of fields including History, Geography, Archaeology, Classics, Genealogy and Modern Languages.
SEA CHANGE will complement the ongoing Pelagios research project, a pioneering multi-year initiative funded by the Andrew W. Mellon Foundation, JISC and the AHRC, that aims to aggregate a large corpus of geographic metadata for geospatial documents from Latin, Greek, European medieval and maritime, as well as early Islamic and Chinese traditions. SEA CHANGE will draw content from similar sources as Pelagios (e.g. the Perseus Digital Library, the Open Philology Project, the Internet Archive or Wikisource), and re-use some of its tools (e.g. the Recogito annotation tool). But in contrast to Pelagios, SEA CHANGE will explore a crowdsourcing approach. It will trial different aspects of collaborative geo-annotation, and ascertain their consequences in terms of data quality, resources required, and participant motivation. Most importantly, however, Dr Rainer Simon highlights:
we are convinced that SEA CHANGE is more than just a means to generate exciting new data relevant to humanities research – it is also a chance to engage with a wider audience and, ultimately, build community.
—
####Open track – Award 2: Early Modern European Peace Treaties Online
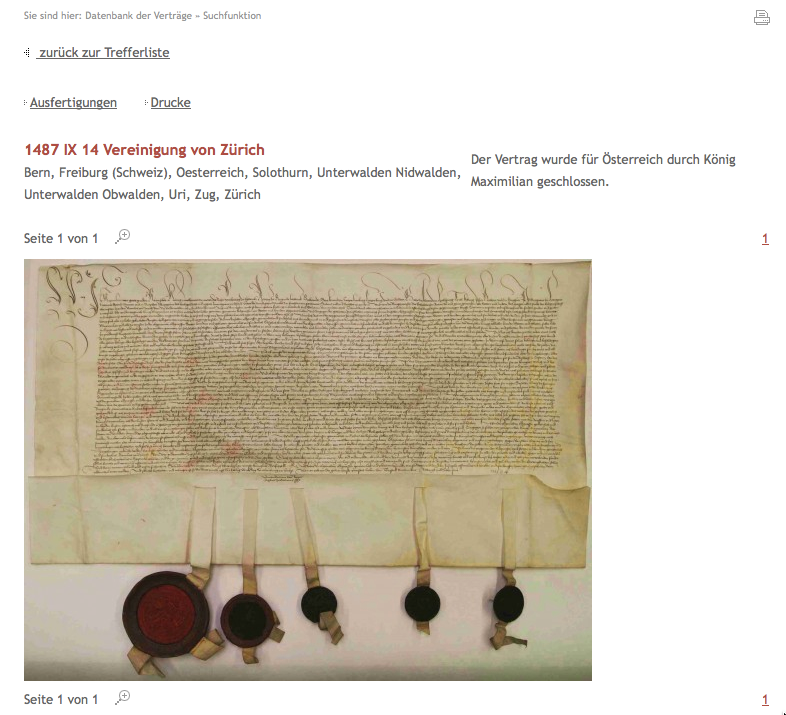
Early Modern European Peace Treaties Online (“Europäische Friedensverträge der Vormoderne online”) is a comprehensive collection of about 1,800 bilateral and multilateral European peace treaties from the period of 1450 to 1789, published as an open access resource by the Leibniz Institute of European History (IEG).
Peace treaties between dynasties and states form an important part of our European cultural heritage. They are also essential for research into early modern peacekeeping and diplomacy. Early Modern European Peace Treaties Online bundles manuscripts that are scattered over archives all over Europe, often hard to access, and partly undocumented. The digitized manuscripts are annotated with basic metadata, and some particularly important treaties are also available as full-text critical editions. This unique combination of digital facsimiles and critical editions has turned out to work as a well-received starting point for scholarly research in this area.
The collection data is currently stored in a relational database with a Web front-end and is one of the most popular digital offerings of IEG. However, it is currently not available as Linked Open Data. This project aims to bring the collection to the Linked Data cloud, which will allow researchers not only to browse the collection but also to use and reuse the data in novel ways and to integrate it with other collections, including Europeana.
The approach foreseen is to represent the key facts of the peace treaties (date, place, signatories, powers, type of treaty, etc.) in RDF using the nanopublications approach, an approach originally developed in the biomedical domain. The publication of the European peace treaties collection as Linked Open Data will make more content and data openly available for researchers to use, and will make it possible to link it to other relevant information, e.g., persons and places via GND/VIAF.
—
####DM2E track – Award: finderApp WITTFind
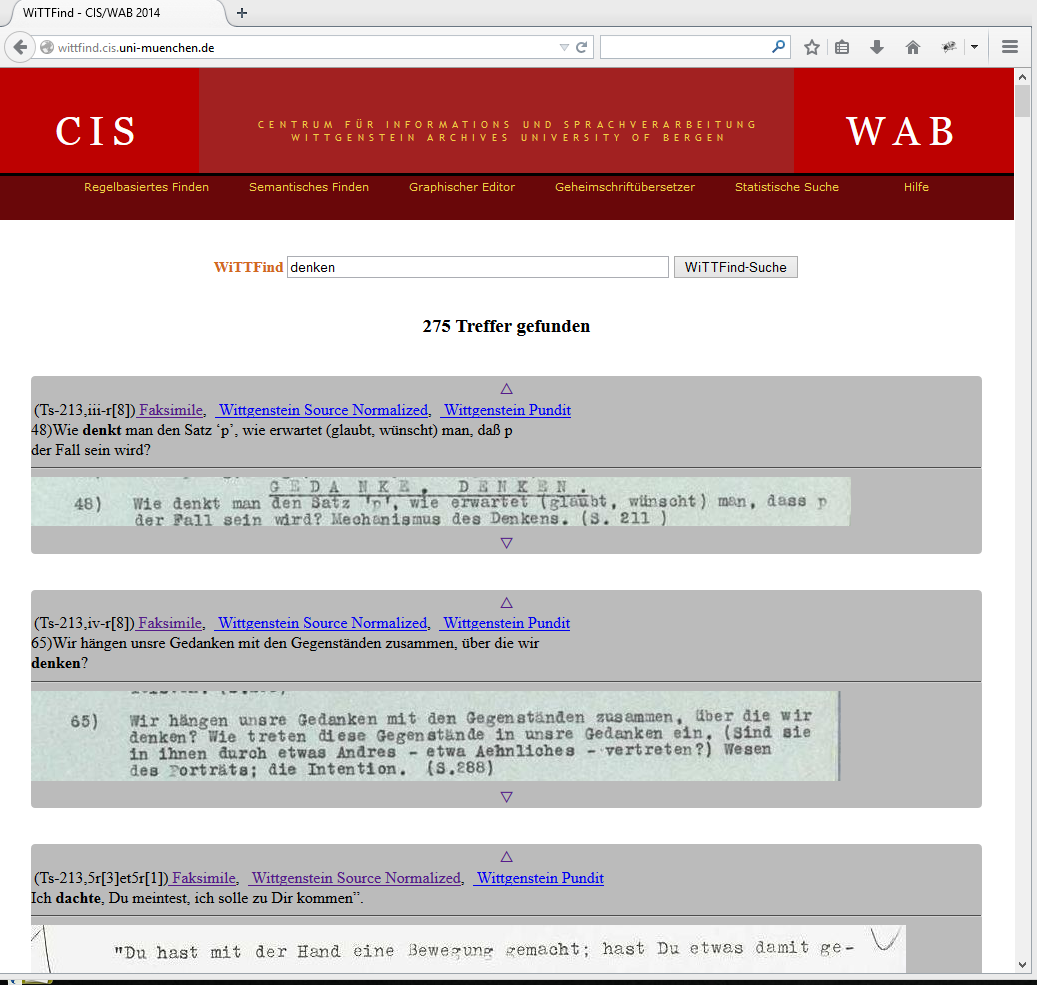
At his death, the Austrian philosopher Ludwig Wittgenstein (1889-1951) left behind 20,000 pages of philosophical manuscripts and typescripts, the Wittgenstein’s Nachlass. In 2009 the Wittgenstein Archives at the University Bergen (WAB), a member of the DM2E project, made 5000 pages from the Nachlass freely available on the web at Wittgenstein Source. Since 2010, the research group “Wittgenstein in Co-Text” has worked on developing the web-frontend finderApp WiTTFind and the “Wittgenstein Advanced Search Tools” (WAST), which provide the possibility of rule-based searching Wittgenstein’s Nachlass in the context of sentences.
The current project finderApp WiTTFind offers to the users and researches in the field of humanities a new kind of search machine. Unlike the search capabilities of Google books and the Open Library project, the tools are rule-based and in combination with electronic lexicon and various computational tools, this project will provide lemmatized and inverse lemmatized search and allow queries to the Nachlass which include word forms, semantic and sentence structured specifications. Syntactic disambiguation is done with Part-of-Speech tagging. Query results are displayed in a web browser as XSLT-transformations of the transcribed texts, together with facsimile of the matching segment in the original. With this information researchers are able to check the correctness of the edition and can explore original handwritten edition-texts which are otherwise stored in access-restricted archives.
The project consists of three elements:
An extension of the finderApp which is currently used for exploring and researching only Ludwig Wittgenstein’s Big Typescript TS-213 (BT) to the rest of the open available 5000 pages of Wittgenstein’s Nachlass
Making the tool openly available to other humanity projects by defining APIs and a XML-TEI-P5 tagset, which defines the XML-structure of the texts which are processed from the finderApp
Building a git-server-site which offers the applications and programs to other research projects in the field of Digital Humanities
***
We congratulate all winners and look forward to seeing the outcomes of their work preseted on the DM2E blog and at upcoming DM2E events in the near future.
After a busy first half of 2014, the DM2E project consortium met at the University of Bergen to discuss the progress made, as well as the upcoming final period of the project. Antoine Isaac of Europeana was invited to present the new Europeana strategy as well as to take part in discussing the link between the technical work done in DM2E and Europeana, especially regarding the aggregation, conversion and ingestion of EDM (Europeana Data Model) data into Europeana. Following on several more detailed presentations on the ongoing research in work packages, there was a session devoted to dissemination of the final results, as well as a debate on the future sustainability of DM2E results, one of the focus points for the final period.
The meeting started with presentations on the results of the last six months by each of the four work package leaders. Their slides are included below.
After this overview, Antoine Isaac gave a presentation on the new Europeana strategy, which is focused on transforming from a platform into a multi-sided portal, offering distinctive value to end users, creatives and professionals. This was followed by a discussion on the ingestion of EDM data from DM2E in Europeana.
Another part of the meeting was devoted to more detailed presentations of the ongoing research in work packages 2 and 3, as well as a demonstration of the new functionality of the Pundit tool by Net7. Dominique Ritze presented updates on the contextualisation tool SILK (integrated in Omnom) through which new linkage rules can be defined to create links between Linked Data resources.
Kai Eckert showed the link DM2E has with the recently started DCMI RDF Application Profiles Task Group (RDF-AP). This group deals with the development of recommendations regarding the proper creation of data models, in particular the proper reuse of existing data vocabularies. The DM2E project was a driving factor in establishing the task group, and the DM2E model will be one of the main case studies.
At the end of the meeting, Steffen Hennicke from the Humboldt University reported on the progress of the research into the scholarly domain model related to the digital humanities. This research focuses on questions such as what kinds of ‘reasoning’ digital humanists want to see enabled by the data and information available in Europeana, and which types of operations digital humanists expect to apply to this data. Several experiments related to this task will be running in the final six months of the project.
In addition, some time was reserved for discussing the dissemination of project results in the final period: there are busy months ahead, with six more DM2E-related events being organised between July and December 2014. The first of these will be the Open Data in Cultural Heritage workshop (15 July, Berlin): more information is available here. All other events will be announced through the DM2E website in the near future. We look forward to a busy and fruitful final period!
While the Digital Humanities community of information scientists, developers and scholarly enthusiasts is making huge progress in the development of tools and virtual research environments (VREs), the vast majority of scholars in the field of Jewish studies rely on traditional methods of research. At the same time digitised primary resources for Jewish studies resources are growing exponentially worldwide.
Jewish Studies were one of the first academic communities to make use of digital resources with the Responsa project which began in 1967.Butis it possible that the present advances in Digital Humanities and many researchers in Jewish studies are like ships in the night that are going to pass by, and probably not meet again?
Ketubah, Herat, 5628 Ḥeshvan 16 [1867 November 14], Ket 270
The Judaica Europeana project and network of libraries, museums and archives which hold digital collections has uploaded millions of digital objects to Europeana. This process continues in the framework of the DM2E and AthenaPlus projects. Led by the European Association for Jewish Culture, the partners in the network will in the coming months integrate in Europeana some of the most valuable resources for Jewish studies: the metadata of the collections from the Center for Jewish History in New York (the YIVO and the Leo Baeck Institutes), the JDC Archives, the Jewish Theological Seminary Library, the Jewish Museum in Prague and many others. The latest Judaica Europeana newsletter presents the highlights of some of these collections.
But will anything be done to ensure that these magnificent collections – digitized at great expense with public or charitable funding ― are used to their full potential? Will the opportunities of the Linked Open Data web and the growing box of open-source tools find many takers in the Jewish Studies community? As they used to say: you can lead a horse to the water, but you can’t make it drink….
Dov Winer, Judaica Europeana’s Scientific Manager, has been arguing for some time that Digital Humanities and LOD have the potential to revolutionize Jewish Studies. The time is ripe: the DM2E project and its experts have been working on modelling the scholarly domain and developing award-winning research tools that respond to the needs of scholars. The DM2E project also provides a platform for the integration of Jewish-content metadata in Europeana.
So what’s next?
DM2E and Judaica Europeana are currently involved in converting vocabularies and encyclopaedias into formats which make them available as Linked Open Data and therefore capable of enriching the metadata of Jewish content and provide contextual meanings. This initiative, which is driven by Dov Winer of EAJC and Kay Eckert of the Research Group on Data and Web Science at Mannheim University, will soon result in the publication of The YIVO Encyclopaedia of Jews in Eastern Europe in a LOD format. The PUNDIT and ASK tools, winners of the 2013 LODLAM Challenge, are freely available with tutorials in four languages, on the DM2E website. The newsletters of Judaica Europeana, disseminated widely to the Jewish studies scholars, have been promoting the Digital Humanities agenda and these new tools to their potential constituencies and users. The work of Judaica Europeana and DM2E will be brought to the attention of participants in the forthcoming Xth Congress of the European Association for Jewish Studies in Paris: on 21 July, our partners will present captivating research in a panel entitled New perspectives on Jewish and non-Jewish relations in modern European culture based on Judaica Europeana digital collections.
Dov Winer, in his paper ‘Feeding Digital Humanities’ argues that what is needed to take all these efforts further is an ongoing virtual infrastructure and a community of practice: a network of scholars committed to using a Virtual Research Environment for their research including a small part-time team to lead it. So far 16 academic researchers from various European universities expressed a strong interest.

 This half-day seminar (taking place from 13.00 – 18.00) will be divided into two parts. In the first part we focus on the work of the content providing partners from the DM2E project. We will share information on how the providers’ content has been used for mappings to Europeana and for publishing delivered metadata as Linked Open Data using the DM2E model, a specialised version of the Europeana Data Model (EDM) for the manuscript domain. In addition, Open Knowledge will be present to talk about the value of open data and the OpenGLAM network.
This half-day seminar (taking place from 13.00 – 18.00) will be divided into two parts. In the first part we focus on the work of the content providing partners from the DM2E project. We will share information on how the providers’ content has been used for mappings to Europeana and for publishing delivered metadata as Linked Open Data using the DM2E model, a specialised version of the Europeana Data Model (EDM) for the manuscript domain. In addition, Open Knowledge will be present to talk about the value of open data and the OpenGLAM network. Towards the closing of our project, we invite all those interested to come to Pisa for the presentation of our final results. Speakers from the DM2E consortium will demonstrate what has been achieved throughout the course of the project and how the tools and communities created have helped to further humanities research in the area of manuscripts in the Linked Open Web.
Towards the closing of our project, we invite all those interested to come to Pisa for the presentation of our final results. Speakers from the DM2E consortium will demonstrate what has been achieved throughout the course of the project and how the tools and communities created have helped to further humanities research in the area of manuscripts in the Linked Open Web.