*This is a guest blog post by Jaap Geraerts. Jaap works as part of the team that won the DM2E Open Humanities Award at the Center for Editing Lives and Letters.*
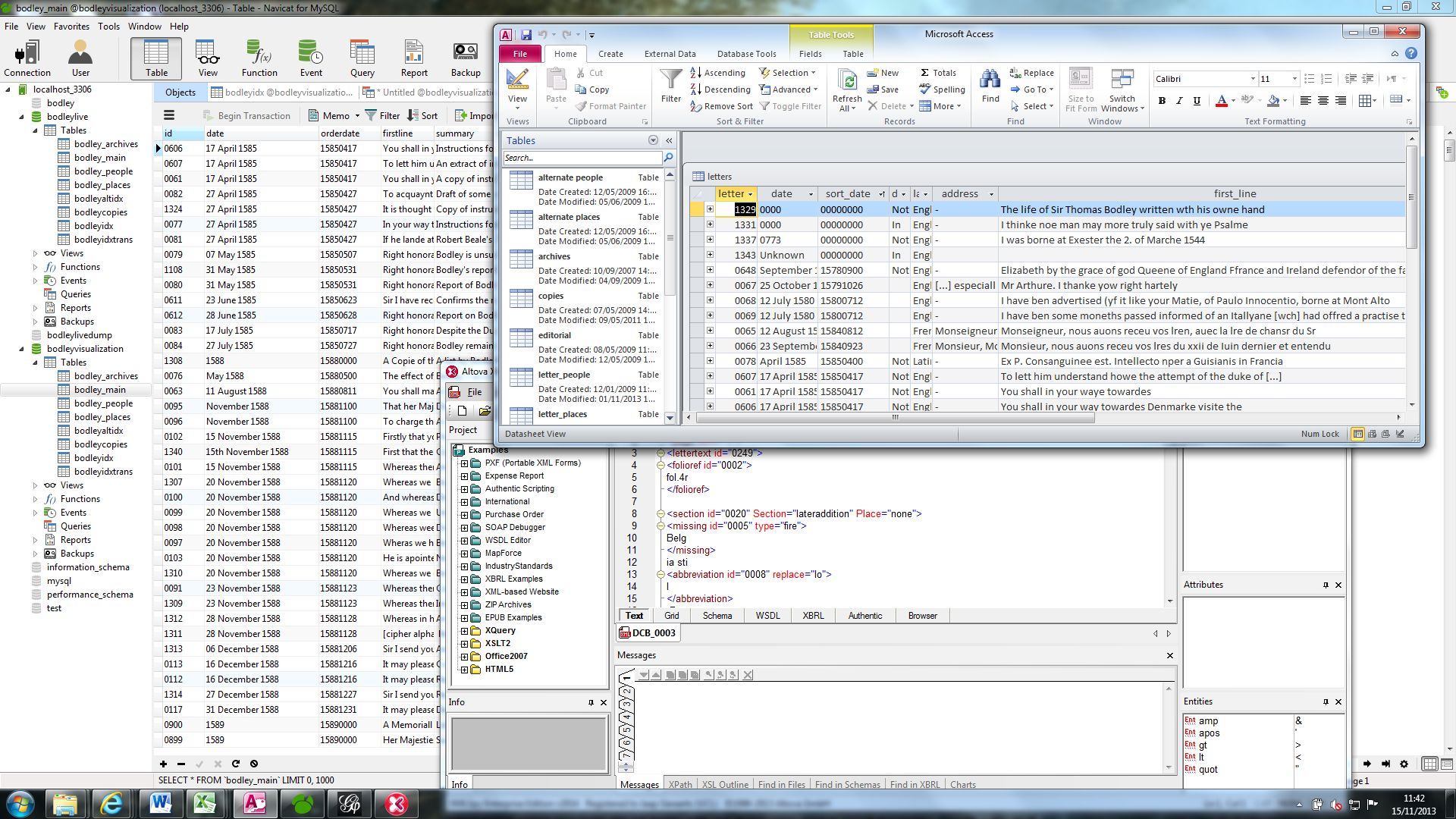
Since the [last update](https://dm2e.eu/open-humanities-awards-joined-up-early-modern-diplomacy-update-3/) about the Joined Up Early Modern Diplomacy project I have devoted a bit of time to the rationalization of the databases which have been created for this project. As the data of the Bodley project is stored in two databases (an ACCESS database and a MySQL database which powers the website) and both of the databases will be used to create the visualizations, it is important to ensure that both databases contain similar data. Moreover, we tried to see which data that was stored in the ACCESS database could be included in the MySQL database in order to enhance our understanding of Bodley’s correspondence network. The XML-files which contain the transcriptions of the letters that are visible on the website of the project had to be updated as well in order to keep them aligned with the updated databases, and all of this shows the work which precedes the creation of the actual visualizations – and I have not even started talking about the whole process of thinking about which visualizations are worth making, a topic which will be addressed in the next blog.
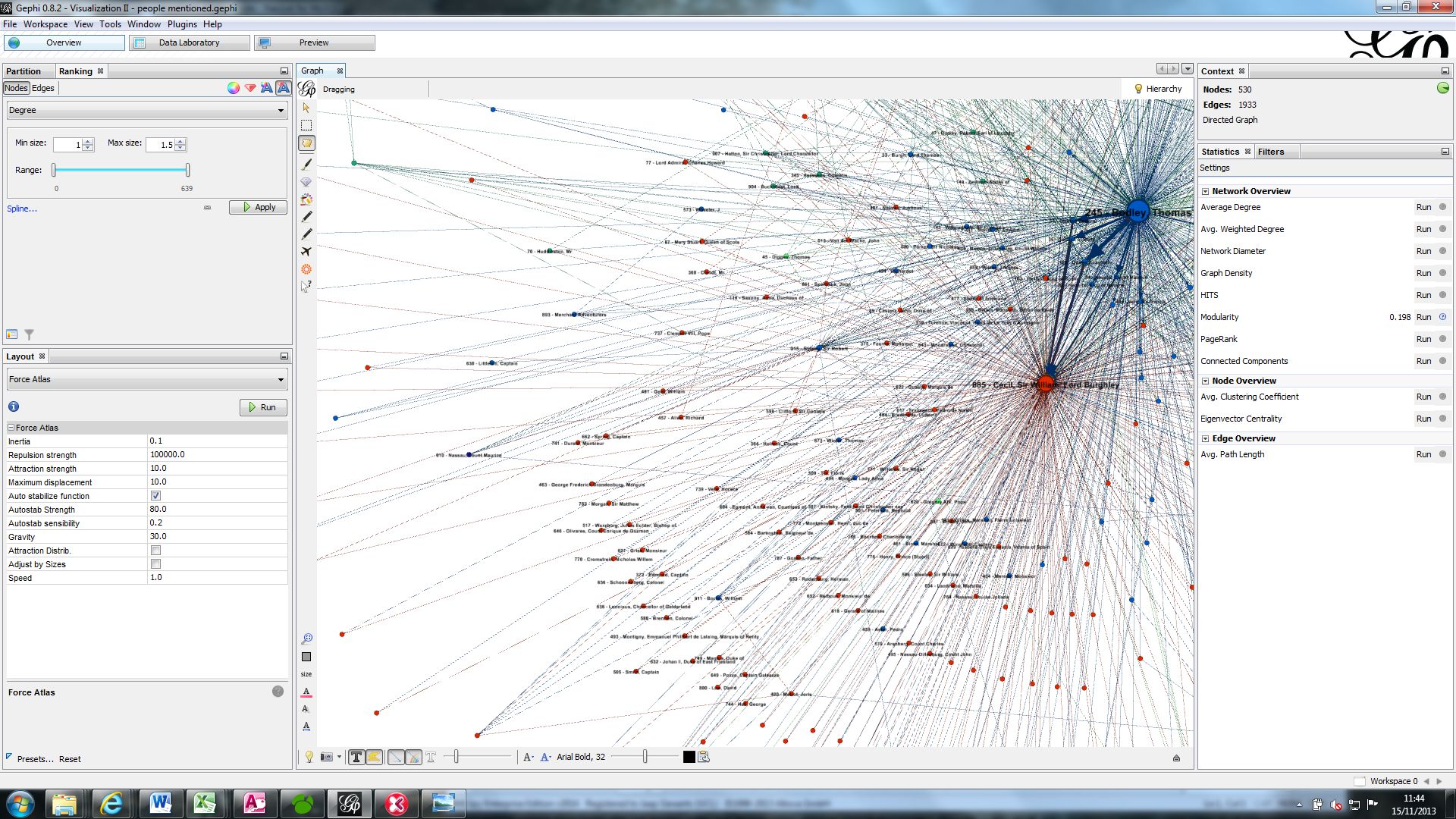
After the process of populating and updating the databases it is time to take the next step towards creating the visualizations, which is the prepare the data to be imported into GEPHI, the software we use to construct the visualizations. As GEPHI requires the data to be presented in a specific format which enables the software to connect the authors to the recipients of the letters and thus to construct the network, the data has to be exported from the database in a particular way.
Moreover, the way GEPHI thus looks at data poses interesting questions about how we view historical data ourselves. For instance, the issue of how to represent the fact that a letter had two or more authors in GEPHI raises the questions whether we should see these historical figures acting as one entity when writing such a letter. In other cases, especially when aiming to move beyond the ‘mere’ visualization of Bodley’s network by including other layers of information, such as the people and places mentioned in the letters, the question is how to capture the historical context and the wealth of the primary sources into a standardized piece of twenty-first-century software. Furthermore, the editorial decisions made by the research team in the development stage of the correspondence project meant that ‘correspondence’ was a fluid term: the bulk of the corpus comprises letters directly to or from Bodley, but also includes items sent in letter packets which, although epistolary in concept, do not necessarily have an addressee (or one that is immediately apparent, e.g. Bodley’s passport and cipher).
The examples given above bear witness to the fact that when using IT-software the researcher is obliged to engage in a dialogue between the software and the historical sources, and it is exactly at this point that IT-skills and the skills of a historian intersect. In addition, these examples serve as a reminder that while IT-software is able to create new insights and helps to address new research questions, a lot of extra work is necessary in order to gain the desired results, which in turn adds scholarly value to the technical resource. In this sense, it is important to remember that the tools embraced by the research taking place within the digital humanities do not magically provide extremely interesting results – rather, using some of these tools is like opening the box of Pandora. In this rapidly changing field of research, then, traditional skills such as scholarly diligence are needed more than ever.
Comments are closed.